

Machine Learning & Generative Poetry (Anderson Ranch 2019 workshop impressions)
As I have done in the last five years I traveled to Aspen this year to the Anderson Ranch to do a week-long workshop on digital art. The workshop I attended was about using machine learning & generative techniques to create poetry!
There is a range of strategies for generating text ranging from classic statistics, various neural networks, randomization, some of which can be done without a computer altogether.
I’ve long been interested in experimenting in this space, as with any field that is going through rapid iteration and business hyperbole it is a ripe area to explore using more esoteric techniques.
Generative systems have been used to create wonderful art pieces over the last few years, mainly focusing on the visual arts. You might have come across some of them, things like the deep dream images, style transfer pieces or GAN art.


Applying generative systems to text, however, is a much smaller field, the only thing that pierced the mainstream that I am aware of is the GPT-2 language model famed for being able to generate text like almost passible news articles with a one-sentence prompt. It holds major academic interest and is a fascinating artifact, but I feel its fun but limited in its artistic and expressive possibilities, at least without some further modification. You can try it here.
There are great artists working in with generative text such as Janelle Shane, Darius Kazemi and Allison Parish who taught my class and whose focus is Poetry specifically.
I am fascinated by the idea that something perceived as so personal expressive and wrapped up in notions authorship and intent can be generated from more abstract rules and systems. It opens it up to challenging avenues of exploration. Throughout the week we discussed the history and theory surrounding the topic as well as learning to use and create various generative systems for text.

We started with learning about the basics of encoding text on computers and what limitations systems like ascii and its descendants have. How for instance would you encode a poem like the one pictured for instance, without resorting to storing at as an image?
We were taught how, as an art practice, generative poetry techniques fit in with artistic movements from the pre-computer era, such as the Dada tradition, where this poem originates from. Or the dream logic of the surrealist, in particular things like the exquisite corpse parlor game. We end at the cut-up techniques as practices by Dadaist such as Tristan Tzara, and later writers like William S. Burroughs and J. G. Ballard who rearranged words by cutting up text into paragraphs or even words and randomly rearranging them.
 We played with some recreations of classic generative poems such as:
We played with some recreations of classic generative poems such as:
The Dada newspaper cutup.
A House of Dust Original by Alison Knowles and James Tenney.
Taroko Gorge by Nick Montfort a nature poem that I really liked.
We started making our poetry generators with tracery. Tracery is a simple replacement grammar system that, given some rules, can generate infinite randomised sentences.

The input is in the curly brackets the output is the text on a grey background. When tracery generates a new sentence it looks at the sentence after “origin” and replaces each word that is preceded by # with a random word in the list with the right word below. It has some special word suffixes .capitilize .s that take care of capitalization and correct pluralization respectively.
What is amazing is that this relatively simple transformation has a huge range of interesting and often funny output. A good example of which is cheapbotsdonequick a website that uses tracery to create a lot of quite interesting twitter bots some of which you might have encountered in the wild already.
You can try a very simple editor to write your own tracery here
I spent quite a bit of time toying with Tracery and I realised that a lot of simple transformation like the one above can work very well if the data, in the form of word lists, is well chosen. For me, it was a very tangible encounter with the artistic potential of data curation. Take the autoflaneur twitter bot for instance. The source code for it is a bit tangled, it gets a slightly more advance with nesting #words inside each other, but you can see that it is mostly just lists of words. I think that in the end, it works so well because the replacement words are so well chosen. The words have cohesion and breathe the same atmosphere, the center point of all these terms together map to a notion of a flaneur.
 The next day we got our hands dirty with the statistical and neural net parts of the course. Starting with the Markov chain! At its heart, it is quite a straightforward statistical model. It describes the chance of going from one state to the next, such as the markets in the image. Based on previous observations you can say that the chance of going from a Bull market to a Bear market is 7.5 % and from a Bull Market to a stagnant market 2.5 % and so on until you connect every state to every other state including itself (the chance of a repeated state).
The next day we got our hands dirty with the statistical and neural net parts of the course. Starting with the Markov chain! At its heart, it is quite a straightforward statistical model. It describes the chance of going from one state to the next, such as the markets in the image. Based on previous observations you can say that the chance of going from a Bull market to a Bear market is 7.5 % and from a Bull Market to a stagnant market 2.5 % and so on until you connect every state to every other state including itself (the chance of a repeated state).
You can also apply this technique to words and predict which word is likely to follow after another, this is where it gets interesting as a budding generative poet. It allows you to generate a new sentence based on prior input! Once you put in a few sentences through a Markov chain, you have ‘trained’ its ‘model’ to look something like the diagram.
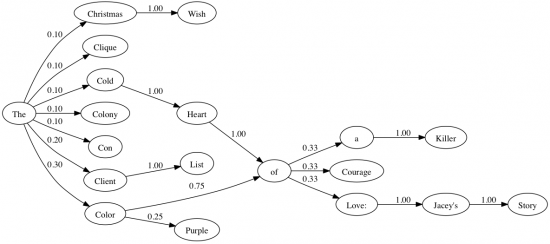
You can use this statistical model that you have trained with text input to generate new text. How? You have the computer roll the proverbial dice. If we start with the word ‘The’ in the diagram, for instance, we have the following probabilities, starting from the bottom:
- 0.00 – 0.30 (30%): Color
- 0.31 – 0.50 (20%): Client
- 0.51 – 0.60 (20%): Con.
- And so on.
Note that they have different chances of being picked, this is the training data at work! In short there is a 30% chance for the word ‘The’ to be followed by the word ‘Color’. So if we randomly generate a number between 0.00 and 1.00 and we get 0.42 we know that after ‘The’ comes ‘Client’, we end up with ‘The Client’. Now we repeat this for each stage in the graph (with much more data) and you can get an idea of how you could generate sentences using this technique.
Next up was an artificial neural network this is the stuff people usually mean when they talk about deep or machine learning. There are a lot of neural networks and the field is fast evolving such as the aforementioned GAN‘s, CNN‘s, VAE‘s and many more. The particular flavour of neural network we worked with was an RNN: a recurrent neural network, this neural network has had some successes with processing and generating text. How these actually work is too specialised to get into here, and I don’t claim to grasp it fully. It involved things like n-dimensional graphs and gradient descent.
 I will, however, give a short explanation that is a gross oversimplification and probably mostly wrong. A Markov chain such as the one above has some shortcomings. Its guesses on what comes next are only based on one point of the graph so it might guess that after the word ‘The’ the word ‘cat’ is likely but it has no memory of any of the previous sentences. Hence a sentence or two later its no more likely to mention a cat than if it had not appeared at all. It has trouble with fundamental written text features such as coherent themes and things like recurring characters.
I will, however, give a short explanation that is a gross oversimplification and probably mostly wrong. A Markov chain such as the one above has some shortcomings. Its guesses on what comes next are only based on one point of the graph so it might guess that after the word ‘The’ the word ‘cat’ is likely but it has no memory of any of the previous sentences. Hence a sentence or two later its no more likely to mention a cat than if it had not appeared at all. It has trouble with fundamental written text features such as coherent themes and things like recurring characters.
Imagine scaling up a Markov chain in such a way that it engages with these higher-order relationships. It can then track things like:
- What are the chances of a ‘cat’ to feature in multiple sentences?
- What are the chances that the words ‘snow’ and ‘heat’ appear in a paragraph?
A neural network such as an RNN ‘notices’ all these higher-order relationships automatically and makes a complex model out of them describing a collection of text.
In an experience similar to my one playing around with GPT-2 I had some trouble with this one, it needs a lot of data and while you can have fun trying to crossbreed books from Project Gutenberg I found it difficult to control and direct.
What I ended up doing as our week drew to a close is to combine two techniques discussed earlier with a third, Spacy! Its a very nice natural language processing programming tool called Spacy, you can try it yourself on the website! It does a lot of different things but one thing it does very well is part of speech tagging. It breakdown a haiku sentence for instance and it breaks it down for you into English grammar.
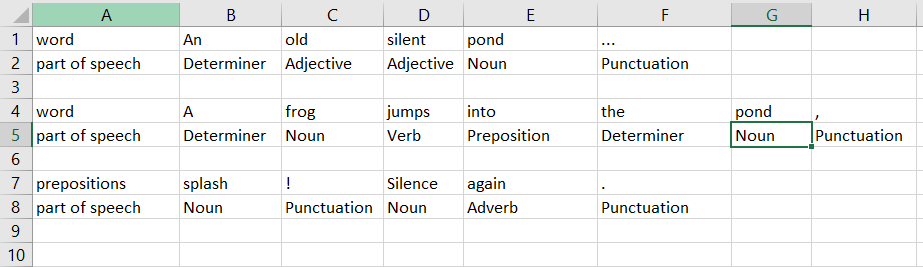
I wrote some of my own traditional original poetry ran that through Spacy and generated a tracery grammar from it.
{
"origin":["#DET.capitalize# #ADJ# #ADJ# #NOUN# #PUNCT#"],
"DET":["the", "all", "this"],
"ADJ":["old", "silent", "young", "gnarled", "pretty", "fragile"],
"NOUN":["pond", "frog", "brook", "river", "pond"],
"PUNCT":["...", ".", "?", "!"]
}
The workshop group went on a trail hike during which I collected and arranged lists of nature verbs, nouns, and adjectives and such. Taking my earlier insight into the artistic potential of data curation I then spent refining these lists and making sure they were part of a cohesive whole.
So by the end of the week, I made a generative system for writing poetry using the following process (slightly simplified):
- Write word lists for parts of speech (e.g. a list for nouns, a list for verbs)
- Write a few poems.
- Break poems down into grammar.
- Train Markov chain on grammar poems.
- Trained Markov chain generates as many new grammar poems as you want.
- Tracery uses new grammar and associated word lists to generate a poem!
I want to thank Anderson Ranch my wonderful classmates and Allison Parish in particular for giving me such a wonderful week! I will leave you with one of the poems I generated.
