

Summary of Reclaim Our Big Data – 29 April 2014
To Care or Not To Care?
Tues 29th April at LBi Digitas, Brick Lane
Watch the video of the event. Choose a speaker from the menu on the right.
Never trust anything that can think for itself if you can’t see where it keeps its brain. – J.K. Rowling, “Dobby’s Reward” Harry Potter and the Chamber of Secrets.
In a flurry of tweets on Cybersalon’s event about Big Data, the above quote was the most retweeted. Big Data, shrouded in “experts only” air of mystery is creating a high level of anxiety as people are losing trust in the government’s care of our personal data. We addressed the opaqueness of Big Data and asked to uncover the “known unknowns” of it by a panel of industry experts.

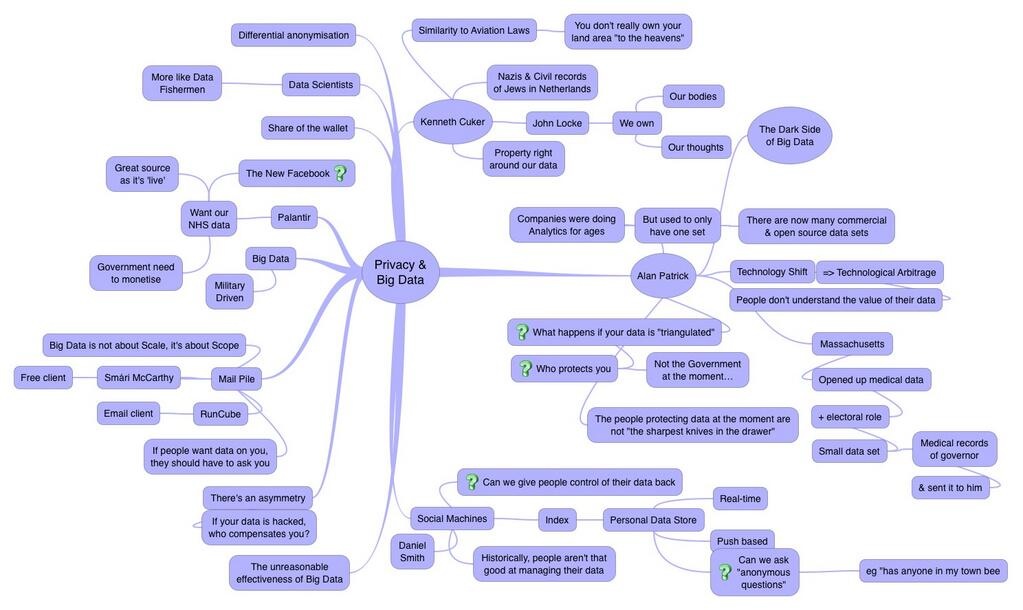
He anchored his framework recalling the debate about farmers right to “the heaven above them” in the US before planes were invented, which was theirs till the aviation industry successfully lobbied for taking that right away.The change was deemed necessary despite the right being clearly previously vested with the farmers. At that time farmers were not organised or connected to each other and had no tools to take on the well-organised military-aviation complex.
Kenneth argues that we are in the same situation of a paradigm shift and need to create clear property rights about the data, that is according to him, a rights-free zone for personal health data.
He also compares the health care data ownership debate to the debate about the drones’ right to fly over your house, pointing out that the drones will have to aquire those rights in order to be useful. At present the right is on the side of the individual, but the technology progress deems that right being an obstacle to ‘progress’– although in this case progress is very ambivalent word.
Kenneth’s view is that the value of providing unlimited access to our personal health data is in providing support to medical research leading to the possible improvements in diagnostics. The idea is that by combining all the sources of unstructured and structured data that the NHS holds on all of us, somehow more knowledge will be gained and we will be able to extend our life expectancies.
He also argues that the data will be anonymised which provides personal data protection.
Alan Patrick (@freecloud) argues against Kenneth optimistic view of anonymisation of Care Data. He points out that anonymisation in this day and age of multiple data sources is simply impossible. As Big Data storage and processing technology (algorithms) became very cheap and easy over the last decade, the option of merging social media sources, demographics, banking and personal health data, the process of de-anonymising is trivial and available to anyone with only basic database skills.
Alan argues that to prevent triangulation of the data, we need to protect individual health data to counter the asymmetry of power between the gatherer of data (government) and the individual whose data is being gathered (the patient).
Wendy M Grossman (@wendyg) supports the idea. She refers to a case of a recent personal privacy campaigner in the US who managed to de-anonymise one of the governors from his health care data and electoral roll, to prove to him that anonymisation is a myth.
Love all, trust a few, do wrong to none. – William Shakespeare

To offer that choice, he is working on a project based in Southampton University that will allow people to store their individual data in Personal Data Storage, like a locker that can “push” the information out if requested for a specific NHS or other medical research project. Under such set up, the user has control over their own data.
He also notes that our sense of privacy is a continuum, or a spectrum that may spam a wide range of sharing of private information, from non-disclosure, to partial disclosure, to full disclosure like one would have with the closest family. Therefore it is not 0 and 1 option for On or Off, but more of a fuzzy framework for the individual to be able to unlock some of the data but not others with a degree of granularity.
Those identity ranges need to be understood and accommodated by the technology underpinning Personal Data Lockers. For example, we still will want to connect to other people who we only know partially, but we should have an option of maintaining wide range of contacts with granular privacy overlaps, case by case.
Daniel also notes that today’s Internet users are notoriously poor with maintaining ‘version control’ of the software they use. It is one element that he recommends being done for them and with User Experience optimisation that will look after their needs whatever level of software hygiene they are able to follow.
Cloud computing is a great euphemism for describing centralisation of computer services under one server – Evgeny Morozov
Smari McCarthy takes a perspective on Big Data from the point of his experiences of increasingly centralised computer services. As noted by Evgeny Morozov, Cloud Computing does not involved any clouds, but simply a centralised computer architecture. Instead of everyone having their email on their own server, as it was the case in the late 90s, we ended up with everyone’s emails (well, 80% of all emails) being hosted by one of the top 10 email providers.
That gives those providers unprecedented control over the User Experience of email world-wide, and also over the user content world-wide, which is being poured over by countless email-reading-robots thousands of times per day.
Smari warns that the societal impact of such an unprecedented and entirely unregulated control over world’s communication leads to societal damage that we are only just beginning to decipher. Even before the Snowden revelations, the EU Parliament was already getting very concerned about the unexpected shift of Internet hosting from thousands of suppliers Europe-wide, to a small handful, dominated by US-based, dumping-price peddling suppliers.
In our discussions on Care Data and NHS, we must reflect on the fact that is a single supplier whose data architecture will by necessity will be centralised, leading to all cyber-security and social risks we have identified with such computer architectures before. The fact that it is state-controlled increases risks, highlighted by poor personal data security record of NHS.
Smari is responding to world-wide centralisation of email but developing an indie-tech product called MailPile, that will offer users protection of the content of their email data.

Discussion
The discussion that follows the presentations starts from voting on audience preferences of options on Care Data. It is noted that in Estonia, the government introduced e-voting and id-numbers with a great support and acceptance from the public. We note that the issue of mistrust in the government does not appear to be present in Scandinavian governments, and that we should acknowledge that lack of trust in the government and the protection of personal data is a specific UK issue. Examining Scandinavian best practice and the roots of trust in government having much wider access to personal data is a direction that we will explore in future Cybersalon research.
A big majority of the audience votes to opt-out of the Care Data as the members consider the risk-and-rewards ratio for the individual simply not tempting enough.
The immediate awards of Care Data are financial, but will not be shared with the patients. The somewhat vague medical gains are way-off, and highly unlikely due to lack of proven methodology of Big Data in the non-surveillance field. The risks are immediate, personal, possibly leading to loss of dignity if there is a leak or de-anonymisation, as noted by Wendy Grossman, considering that people share very deeply personal information with their GP. The public is being asked to take the pain, but not to share the gain.
Longer term Personal Data Storage and indie tech like MailPile will help with the personal data security. However, short term, we need to protect the public and ourselves by technical solutions.
Therefore we conclude that unless the above risks are addressed, and a Big Data Council is formed to oversee the process of personal health data disclosure, opting out of the scheme is the only solution to avoid the risks.
Eva Pascoe
“I would rather trust a women’s instinct than a man’s reason” are the words of Stanley Baldwin quoted by Eva Pascoe (@evapascoe) who points out that in the times of a £107bn UK budget deficit, the government is justified in looking to monetise the NHS. Its current cost of £107bn is going to explode even more as forecasters expect an increase of 20% of people over 65 over next 20 years. However, the government’s announcements of Care Data were misleading as the motivation for the project was explained in terms of a possibility of future improvements in medical knowledge, and not in terms of commercial monetisation that will take place, benefiting the government.
There is a substantial difference of goals as the public perceives the situation as the risk being placed on the individual, but the rewards going to the government.
Woman are the majority of users of NHS, and are in contact with the NHS more often due to child bearing, the child care process and their caring role. Their perception of risks of sharing their GP files with a medical insurance or drug company from far away lands was immediately noted as a no-no, as exemplified by the proposed amendments to Care Data by Prof Allyson Pollock.
She also notes that NHS has already lost people’s trust before the Care Data debacle, as in January 2012 it sold data of 43m patients from the previous 20 years without seeking public acceptance. In addition, the NHS has got a very poor ‘data protection culture’, appearing frequently in the press for leaking unencrypted patient data by leaving the records on old but not decommissioned laptops and frequently suffering from other examples of lack of cybersecurity competence. Nobody gets fired for losing data in the civil service and therefore the government does not enjoy any degree of trust from the public in their ability to handle public data.
Pascoe (pioneer of e-CRM in UK, former MD of Topshop Online, and online data privacy campaigner also noted that traditional retail brands do enjoy the trust of their customers in terms of personal data protection, and we should look at how that trust is achieved as an example of best practice.
The traditional UK-based large fashion brands like Topshop, Topman or Next have introduced electronic CRMs and dealt with large sets of personal data since the 90s. These were publicly owned companies and followed EU data protection law with opt-out options for the customers.
They also offered access to records individual data if asked by the data owner, as per EU legal requirements (Data Protection Act). If anyone asks Google for that file today, they will just think you are having a laugh. Topshop also recognised the value of the data it obtained from the customer and offered 10% discount to customers who were willing to give data to the retailer, implemented via their Store Card.
However, with the arrival of US e-tail like Amazon and E-bay, the EU data protection has lost its bite as the catalogue-based US data culture does not recognise the right of the customer in Europe to own their data. US companies rode roughshod over the EU personal data sensitivities and lobbied heavily in EU legal scene to overturn the hard fought for personal data protection. The perception that the personal data is “the new oil” has taken roots with arrival of Facebook in 2004.
Pascoe notes that Big Data companies since their inception about 2004 have been driven by military and surveillance applications. Companies like Palantir (also known affectionately as ‘Spy-lantir’), co-owned by E-bay investor Peter Thiel lead the way in unstructured data processing for Big Brother and UK governmental security agencies, and contributed to the Prism surveillance program. She points out that the way to tell the Big Data-Big Brother players is to look at their logo – the cuddlier the logo, the more sinister the company (note cuddly yellow elephant and smiling bee that signify Hadoop and Claudera, major Big Data and surveillance industry players, since inception funded by CIA (via Intel-Q-Tel) but branding themselves as civilian outfits.
Palantir.com is contracted to process Big Data for UK government using their Data Scientists (also known as “data fishermen” due to somewhat exploratory nature of their data adventures). Pascoe argues that there are significant doubts about how scientific Big Data procedures are, as they are not standardized, non-verifiable, non-peer reviewed and without any way of external verification. The results of the analysis are not published for others to replicate or examine.
Therefore the big prize of a new cure for cancer to be achieved via Big Data is a very long shot it terms of the scientific evidence of the usefulness of this technology so far for anything more than finding what brands people chat about on social media.
Pascoe comments that Facebook is not really free and that we pay for the service with our data. Pascoe asks if the NHS is the New Facebook, and are we going to be asked to pay for the ‘free health service’ with our personal data. If that is the case, personal health data needs to be protected from being sold to commercial companies without incurring security leaks and losing the value that the data carry. The government is asking us to take a massive risk and allow use of personal data for free today, to anNHS that is notorious for losing data, in the context where the reward is only a very vague future gain of some (unqualified and unproven methodologically) improvements in medical knowledge years from today, in fact probably way-off in the future.
It is clear that the decision makers do not understand or appreciate the public risk perception on the issue of health data as well as tax data security and are being influenced by the Big Data military-led suppliers, hungry for contracts and hungry for our data.
——————————————————————————————————
Speakers Notes
Kenneth Cukier – The Algorithm Will Get You
Kenneth Cukier is the Data Editor for The Economist, following a decade at the paper covering business and technology, and as a foreign correspondent (most recently in Japan from 2007-12). Previously he was the technology editor of the Wall Street Journal Asia in Hong Kong and worked at the International Herald Tribune in Paris. From 2002-2004 he was a research fellow at Harvard’s Kennedy School of Government. He is the co- author of “Big Data: A Revolution that Will Transform How We Work, Live and Think” (2013).
He looks at Big Data as it raises a host of worries for which society is unprepared. What does it mean if big data denies us a bank loan or considers us unfit for a surgical operation, but we can’t learn the explicit reasons because the variables that went in were so myriad and complex? How do you regulate an algorithm? How do you regulate an algorithm that only a tiny handful of people on the planet understand?
Smári McCarthy- Privacy, Security and Mailpile
Smári is the director of the International Modern Media Institute, a skilled programmer and a prominent member of the Icelandic Pirate Party. He is also a sought after speaker who travels to far away lands, teaching journalists and activists how to communicate securely on-line. He has developed Mailpile- an encrypted web mail client.
Alan Patrick -The Myth of Anonymisation
Alan Patrick co founded Broadsight after a career both consulting to, and working at, senior level for leading global multimedia companies such as the BBC, British Telecom (OpenWorld and Ignite), AOL Time Warner, ntl and UPC. He was Managing Director and COO at Jacobs Rimell, who specialise in multi-media OSS systems. He also held positions as VP Corporate Development for Globix Corporation in New York, Head of Internet Business Development at British Telecom, and consulted widely on multimedia to a number of major TV and cable companies in his consulting career at McKinsey and PriceWaterhouseCoopers.
Big Data is not about big data, which we have always had, but about cheap storage and computational power. Big Data is really Big Computation and Storage. What is possible now that was not possible before Big Data? Current use of Open Data and Big Computing to drive products for commercial purposes, utilising triangulation of Open Data and other freely available data leads to risk of de-anonymisation, which were not so apparent in the small data period. Can privacy be “baked-in” as in Jeff Jonas project at IBM – creating a system (G2) that has privacy “baked in” such that it’s not possible to remove it later? Other proposals include Cynthia Dwork’s differential privacy, which requires you to set the number of queries you will make of a database and burn it once those are finished.’
Daniel A. Smith- Supporting Modern Data Needs, The INDX Personal Data Store
Daniel is a Research Fellow with the SOCIAM Project at the University of Southampton. Daniel holds a PhD and a Master of Engineering in Computer Science from the University of Southampton, where he researched large scale exploration of heterogeneous data. He works on INDX, an open-source personal data store designed for long-term secure personal data storage and sharing. Daniel’s research interests include personal data, open/government data, the semantic web, decentralised architectures, social machines, information security, and privacy, and has over 60 peer-reviewed works in conferences, workshops, and journals.
Some of his writing is here:
http://eprints.soton.ac.uk/363496/1/w15socm14-vankleek.pdf
http://eprints.soton.ac.uk/362097/1/chi2014-padd-wip-final_submitted_to_sheridan.pdf
Chair: Wendy M. Grossman- technology journalist and writer and the 2013 winner of the Enigma Award.
Big Data emerged from scientific projects that needed to host a rather large amount of data. The Hadron Collider, large astronomy or geology projects routinely handle terabytes or even petabytes of data without breaking a sweat. However, recently Big Data, made famous by Google’s Flu Trends, has spread like a dangerous Ebola virus beyond basic science and is poking its omnipresent analytical big eye into everyone’s online life.
Our ‘found data’ – such as medical and commuter data- is turning ad agency Mad Men into Math Men. The glamour of Big Data is becoming very tempting for governments who are increasingly building up their technological armoury to handle giant sets of data like those used in online surveillance.
With increased knowledge and ability to suck out the Big Data from us all, who is to win and who is to lose in the new cyber-battleground? Where are we on statistical knowledge of the pitfalls of Big Data as the threat of The End of Causation is looming on the horizon?
With Big Data, as with any other data technologies, the power will be on the side that gathers the data, not the side that provides it.
At Cybersalon our four experts will examine the new risks of the Big Data phenomenon, the impact on our daily lives, as well as look at the opportunities for new tools as we get a better handle on this potentially exciting new industry.
In order to solve medical or mega-city living challenges, we will all should be benefit from Big Data. But considering this will be a commercial process, how can we make sure the data we produce, we own and benefit from the upside as a collective as well as an individual.



