

Originally published on the net.wars column on June 16th, 2017
Humans are a problem in decision-making. We have prejudices based on limited experience, received wisdom, weird personal irrationality, and cognitive biases psychologists have documented. Unrecognized emotional mechanisms shield us from seeing our mistakes.
Cue machine learning as the solution du jour. Many have claimed that crunching enough data will deliver unbiased judgements. These days, this notion is being debunked: the data the machines train on and analyze arrives pre-infected, as we created it in the first place, a problem Cathy O’Neil does a fine job of explaining in Weapons of Math Destruction. See also Data & Society and Fairness, Accountability, and Transparency in Machine Learning.
interview for New Scientist in 2003 ($)Patrick Ball*, founding director of the Human Rights Database Analysis Group, argues, however, that there are underlying worse problems. HRDAG “applies rigorous science to the analysis of human rights violations around the world”. It uses machine learning – currently, to locate mass graves in Mexico – but a key element of its work is “multiple systems estimation” to identify overlaps and gaps.
“Every kind of classification system – human or machine – has several kinds of errors it might make,” he says. “To frame that in a machine learning context, what kind of error do we want the machine to make?” HRDAG’s work on predictive policing shows that “predictive policing” finds patterns in police records, not patterns in occurrence of crime.
Media reports love to rate machine learning’s “accuracy”, typically implying the percentage of decisions where the machine’s “yes” represents a true positive and its “no” means a true negative. Ball argues this is meaningless. In his example, a search engine that scans billions of web pages for “Wendy Grossman” can be accurate to .99999 because the vast supply of pages that don’t mention me (true negatives) will swamp the results. The same is true of any machine system trying to find something rare in a giant pile of data – and it gets worse as the pile of data gets bigger, a problem net.wars has often called searching for a needle in a haystack by building bigger haystacks in relation to data retention.
For any automated decision system, you can draw a 2×2 confusion matrix, like this:
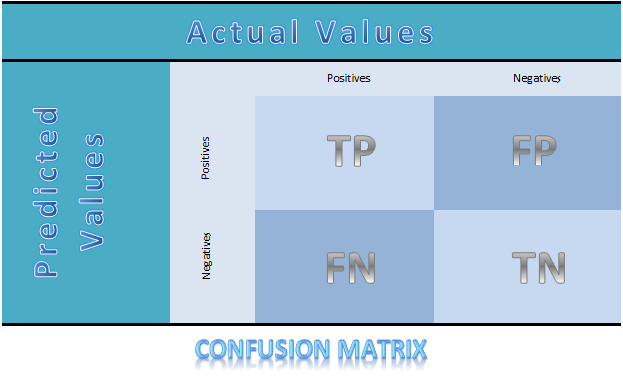
“There are lots of ways to understand that confusion matrix, but the least meaningful of those ways is to look at true positives plus true negatives divided by the total number of cases and say that’s accuracy,” Ball says, “because in most classification problems there’s an asymmetry of yes/no answers” – as above. A “94% accurate” model “isn’t accurate at all, and you haven’t found any true positives because these classifications are so asymmetric.” This fact does make life easy for marketers, though: you can improve your “accuracy” just by throwing more irrelevant data at the model. “To lay people, accuracy sounds good, but it actually isn’t the measure we need to know.”
Unfortunately, there isn’t a single measure: “We need to know at least two, and probably four. What we have to ask is, what kind of mistakes are we willing to tolerate?”
In web searches, we can tolerate a few seconds to scan 100 results and ignore the false positives. False negatives – pages missing that we wanted to see – are less acceptable. Machine learning uses “recall” for the fraction of true positives in the set of results, and “precision” for that of true positives in the entire set being searched. The various ways the classifier can be set can be drawn as a curve. Human beings understand a single number better than tradeoffs; reporting accuracy then means picking a spot on the curve as the point to set the classifier. “But it’s always going to be ridiculously optimistic because it will include an ocean of true negatives.” This is true whether you’re looking for 2,000 fraudulent financial transactions in a sea of billions daily, or finding a handful of terrorists in the general population. Recent attackers, from 9/11 to London Bridge 2017, have already been objects of suspicion, but forces rarely have the capacity to examine every such person, and before an attack there may be nothing to find. Retaining all that irrelevant data may, however, help forensic investigation.
Where there are genuine distinguishing variables, the model will find the matches even given extreme asymmetry in the data. “If we’re going to report in any serious way, we will come up with lay language around, ‘we were trying to identify 100 people in a population of 20,00 and we found 90 of them.” Even then, care is needed to be sure you’re finding what you think. The classic example here is the the US Army’s trial using neural networks to find camouflaged tanks. The classifier fell victim to the coincidence that all the pictures with tanks in them had been taken on sunny days and all the pictures of empty forest on cloudy days. “That’s the way bias works,” Ball says.
 The crucial problem is that we can’t see the bias. In her book, O’Neil favors creating feedback loops to expose these problems. But these can be expensive and often can’t be created – that’s why the model was needed.
The crucial problem is that we can’t see the bias. In her book, O’Neil favors creating feedback loops to expose these problems. But these can be expensive and often can’t be created – that’s why the model was needed.
“A feedback loop may help, but biased predictions are not always wrong – but they’re wrong any time you wander into the space of the bias,” Ball says. In his example: say you’re predicting people’s weight given their height. You use one half of a data set to train a model, then plot heights and weights, draw a line, and use its slope and intercept to predict the other half. It works. “And Wired would write the story.” Investigating when the model makes errors on new data shows the training data all came from Hong Kong schoolchildren who opted in, a bias we don’t spot because getting better data is expensive, and the right answer is unknown.
“So it’s dangerous when the system is trained on biased data. It’s really, really hard to know when you’re wrong.” The upshot, Ball says, is that “You can create fair algorithms that nonetheless reproduce unfair social systems because the algorithm is fair only with respect to the training data. It’s not fair with respect to the world.”
Illustrations: Patrick Ball; confusion matrix (Jackverr); Cathy O’Neil (GRuban).
Wendy M. Grossman is the 2013 winner of the Enigma Award. Her Web site has an extensive archive of her books, articles, and music, and an archive of earlier columns in this series. Stories about the border wars between cyberspace and real life are posted occasionally during the week at the net.wars Pinboard – or follow on Twitter.




{kind=link}
{kind=link}